
AI-wet
De AI-wet is het allereerste wettelijk kader voor AI, dat de risico’s van AI aanpakt en Europa wereldwijd een leidende rol geeft.
De AI-wet (Verordening (EU) 2024/1689 tot vaststelling van geharmoniseerde regels inzake kunstmatige intelligentie) is wereldwijd het allereerste uitgebreide wettelijke kader voor AI. Het doel van de regels is om betrouwbare AI in Europa te bevorderen.
De AI-wet bevat een duidelijke reeks risicogebaseerde regels voor AI-ontwikkelaars en -invoerders met betrekking tot specifieke toepassingen van AI. De AI-wet maakt deel uit van een breder pakket beleidsmaatregelen ter ondersteuning van de ontwikkeling van betrouwbare AI, waaronder ook het AI-innovatiepakket, de lancering van AI-fabrieken en het gecoördineerde plan voor AI. Samen garanderen deze maatregelen veiligheid, fundamentele rechten en mensgerichte AI, en versterken ze de toepassing, investeringen en innovatie in AI in de hele EU.
Om de overgang naar het nieuwe regelgevingskader te vergemakkelijken, heeft de Commissie het AI Pact gelanceerd, een vrijwillig initiatief dat de toekomstige implementatie wil ondersteunen, met belanghebbenden wil samenwerken en AI-aanbieders en -inzetverstrekkers uit Europa en daarbuiten wil uitnodigen om zich vroegtijdig te houden aan de belangrijkste verplichtingen van de AI Act.
Waarom hebben we regels voor AI nodig?
De AI Act zorgt ervoor dat Europeanen kunnen vertrouwen op wat AI te bieden heeft. Hoewel de meeste AI-systemen weinig tot geen risico’s met zich meebrengen en kunnen bijdragen aan het oplossen van veel maatschappelijke uitdagingen, creëren bepaalde AI-systemen risico’s die we moeten aanpakken om ongewenste uitkomsten te voorkomen.
Zo is het vaak niet mogelijk om te achterhalen waarom een AI-systeem een beslissing of voorspelling heeft genomen en een bepaalde actie heeft ondernomen. Het kan dus moeilijk worden om te beoordelen of iemand onterecht benadeeld is, bijvoorbeeld bij een beslissing tot aanstelling of bij een aanvraag voor een uitkering.
Hoewel de bestaande wetgeving enige bescherming biedt, is deze onvoldoende om de specifieke uitdagingen aan te pakken die AI-systemen met zich mee kunnen brengen.
Een risicogebaseerde aanpak
De AI-wet definieert vier risiconiveaus voor AI-systemen:
Piramide met de vier risiconiveaus: Onaanvaardbaar risico; Hoog risico; Beperkt risico, minimaal of geen risico
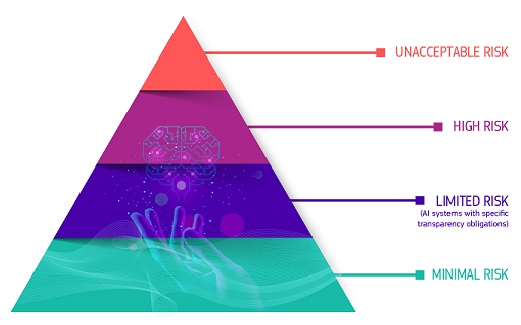
Alle AI-systemen die als een duidelijke bedreiging voor de veiligheid, het levensonderhoud en de rechten van mensen worden beschouwd, zijn verboden. De AI-wet verbiedt acht praktijken, namelijk:
schadelijke AI-gebaseerde manipulatie en misleiding
schadelijke AI-gebaseerde uitbuiting van kwetsbaarheden
sociale scoring
Individuele risicobeoordeling of -voorspelling van strafbare feiten
Ongerichte scraping van internet of CCTV-materiaal om gezichtsherkenningsdatabases te creëren of uit te breiden
emotieherkenning op de werkplek en in onderwijsinstellingen
biometrische categorisatie om bepaalde beschermde kenmerken af te leiden
realtime biometrische identificatie op afstand voor rechtshandhavingsdoeleinden in openbaar toegankelijke ruimtes
Hoog risico
AI-toepassingen die ernstige risico’s kunnen vormen voor de gezondheid, veiligheid of grondrechten, worden geclassificeerd als hoog risico. Deze risicovolle use cases omvatten:
AI-veiligheidscomponenten in kritieke infrastructuren (bijv. transport), waarvan het uitvallen het leven en de gezondheid van burgers in gevaar kan brengen.
AI-oplossingen die worden gebruikt in onderwijsinstellingen en die de toegang tot onderwijs en het verloop van iemands beroepsleven kunnen bepalen (bijv. het beoordelen van examens).
AI-gebaseerde veiligheidscomponenten van producten (bijv. AI-toepassing in robotgeassisteerde chirurgie).
AI-tools voor werkgelegenheid, personeelsbeheer en toegang tot zelfstandig ondernemerschap (bijv. cv-sorteersoftware voor werving).
Bepaalde AI-use cases die worden gebruikt om toegang te geven tot essentiële private en publieke diensten (bijv. kredietscores die burgers de mogelijkheid ontzeggen om een lening te krijgen).
AI-systemen die worden gebruikt voor biometrische identificatie op afstand, emotieherkenning en biometrische categorisatie (bijv. een AI-systeem om achteraf een winkeldief te identificeren).
AI-use cases in rechtshandhaving die de fundamentele rechten van mensen kunnen schenden (bijv. de beoordeling van de betrouwbaarheid van bewijs).
AI-use cases in migratie-, asiel- en grenscontrolebeheer. (bijv. geautomatiseerde beoordeling van visumaanvragen)
AI-oplossingen die worden gebruikt in de rechtsbedeling en democratische processen (bijv. AI-oplossingen ter voorbereiding van rechterlijke uitspraken)
AI-systemen met een hoog risico zijn onderworpen aan strenge verplichtingen voordat ze op de markt kunnen worden gebracht:
adequate systemen voor risicobeoordeling en -beperking
hoge kwaliteit van de datasets die het systeem voeden om de risico’s van discriminerende uitkomsten te minimaliseren
registratie van activiteiten om de traceerbaarheid van resultaten te waarborgen
gedetailleerde documentatie met alle benodigde informatie over het systeem en het doel ervan, zodat autoriteiten de naleving ervan kunnen beoordelen
duidelijke en adequate informatie aan de uitvoerder
passende maatregelen voor menselijk toezicht
hoge mate van robuustheid, cyberbeveiliging en nauwkeurigheid
transparantierisico
Dit verwijst naar de risico’s die gepaard gaan met de behoefte aan transparantie rond het gebruik van AI. De AI-wet introduceert specifieke openbaarmakingsverplichtingen om ervoor te zorgen dat mensen worden geïnformeerd wanneer dat nodig is om het vertrouwen te behouden. Bij het gebruik van AI-systemen zoals chatbots moeten mensen er bijvoorbeeld van bewust worden gemaakt dat ze met een machine communiceren, zodat ze informatie kunnen opnemend besluit.
Bovendien moeten aanbieders van generatieve AI ervoor zorgen dat door AI gegenereerde content identificeerbaar is. Bovendien moet bepaalde door AI gegenereerde content duidelijk en zichtbaar worden gelabeld, met name deepfakes en tekst die wordt gepubliceerd om het publiek te informeren over zaken van algemeen belang.
Minimaal of geen risico
De AI-wet introduceert geen regels voor AI die als minimaal of geen risico wordt beschouwd. De overgrote meerderheid van de AI-systemen die momenteel in de EU worden gebruikt, valt in deze categorie. Dit omvat toepassingen zoals AI-gestuurde videogames of spamfilters.
Hoe werkt dit in de praktijk voor aanbieders van AI-systemen met een hoog risico?
Hoe werkt dit in de praktijk voor aanbieders van AI-systemen met een hoog risico?
Stapsgewijs proces voor conformiteitsverklaring
Zodra een AI-systeem op de markt is, zijn de autoriteiten verantwoordelijk voor het markttoezicht, zorgen exploitanten voor menselijk toezicht en monitoring, en beschikken aanbieders over een systeem voor post-market monitoring. Aanbieders en exploitanten melden ook ernstige incidenten en storingen.
Een oplossing voor het betrouwbare gebruik van grote AI-modellen
Algemene AI-modellen kunnen een breed scala aan taken uitvoeren en vormen de basis voor veel AI-systemen in de EU. Sommige van deze modellen kunnen systeemrisico’s met zich meebrengen als ze zeer capabel zijn of op grote schaal worden gebruikt. Om veilige en betrouwbare AI te garanderen, stelt de AI-wet regels vast voor aanbieders van dergelijke modellen. Dit omvat transparantie- en auteursrechtregels. Voor modellen die systeemrisico’s met zich mee kunnen brengen, moeten aanbieders deze risico’s beoordelen en beperken.
De regels van de AI-wet inzake algemene AI treden in augustus 2025 in werking. Het AI-Bureau faciliteert het opstellen van een gedragscode om deze regels te specificeren. De code moet een centraal instrument vormen voor aanbieders om naleving van de AI-wet aan te tonen, met inbegrip van de modernste praktijken.
Bestuur en implementatie
Het Europees AI-Bureau en de autoriteiten van de lidstaten zijn verantwoordelijk voor de implementatie, het toezicht en de handhaving van de AI-wet. De AI-Raad, het Wetenschappelijk Panel en het Adviesforum sturen en adviseren over het bestuur van de AI-wet. Meer informatie over het bestuur en de handhaving van de AI-wet.